How I Turned a 40-Hour App Factory Into a 6-Hour One
The story of how I dissected an entire app development pipeline, and built a multi-agent AI system that changed everything.
When I walked in, the average app took 40 hours to build. When I left, it took 6. This is the story of how I got there. I din't happen with one big breakthrough, but by obsessively watching people work and asking, over and over, "Why is a human doing this?"
The assignment
I was brought in with a simple mandate: find every bottleneck in the app creation pipeline and improve what could be improved. The company builds mobile apps at scale, dozens of them, all following similar patterns. They knew the process was slower than it could be. They just didn't know where the time was going.
So that's where I started. Just watching.
Weeks of watching
I spent the first few weeks doing something that probably looked unproductive from the outside. I sat with engineers. I asked questions. I timed things. I mapped out every single step from the moment a feature request landed to the moment an app hit review.
I tracked how long each phase took across multiple projects and built a picture of where the hours actually went. Some of what I found was expected. Some of it wasn't.
A surprising amount of time, about three hours per app, was spent on pure setup. Creating the google cloud project, the Firestore database, spinning up a GitHub repo, etc. None of this required creativity or judgment. It was the same sequence of clicks and commands every single time, just with different strings plugged in. And it actually required a lot of attention as any error in that setup could end up with security misconfigurations or hard to track bugs.
Then there was the core engineering: translating a feature description into architecture, architecture into boilerplate, boilerplate into components, components into tests. This was where the real hours lived. And the more I watched, the more I noticed something: engineers weren't really engineering for most of it. They were translating. Taking well-understood patterns and rewriting them in a slightly different context. Over and over.
I had my map. Now I needed a plan.
Phase one: automate the obvious
I started with the deterministic stuff. Everything that happened the same way every time, just with different parameters.
I wrote a single script that would take an app name and a basic config, and in about ten minutes:
- Provision the Firestore database with the right collections and rules
- Create and configure the GitHub repository
- Set up the full CI/CD pipeline
- Scaffold the initial Flutter project with the company's base architecture
Automated. No human in the loop. All launched from a Google Chat app.
That alone shaved three hours off every single app. All that was left to do is for the engineer to git clone the fresh git repo. It saved precious time and it eliminated an entire category of configurations bugs.
But the setup wasn't where the real time was hiding. The real target was the core development loop.
Phase two: the agent pipeline
Once the deterministic automation was in place, I turned to the harder problem: could AI handle the translation work that was eating up 80% of engineering time?
The insight came from watching what developers actually do when they build an app. They're not doing one continuous thing. They're context-switching between well-defined roles: requirements analyst, architect, scaffolder, implementer, tester, each with clear inputs and outputs. That's a workflow you can decompose.
I decided to build it as a system of specialized agents, each owning one slice of the pipeline, orchestrated by LangGraph into a single coherent flow:
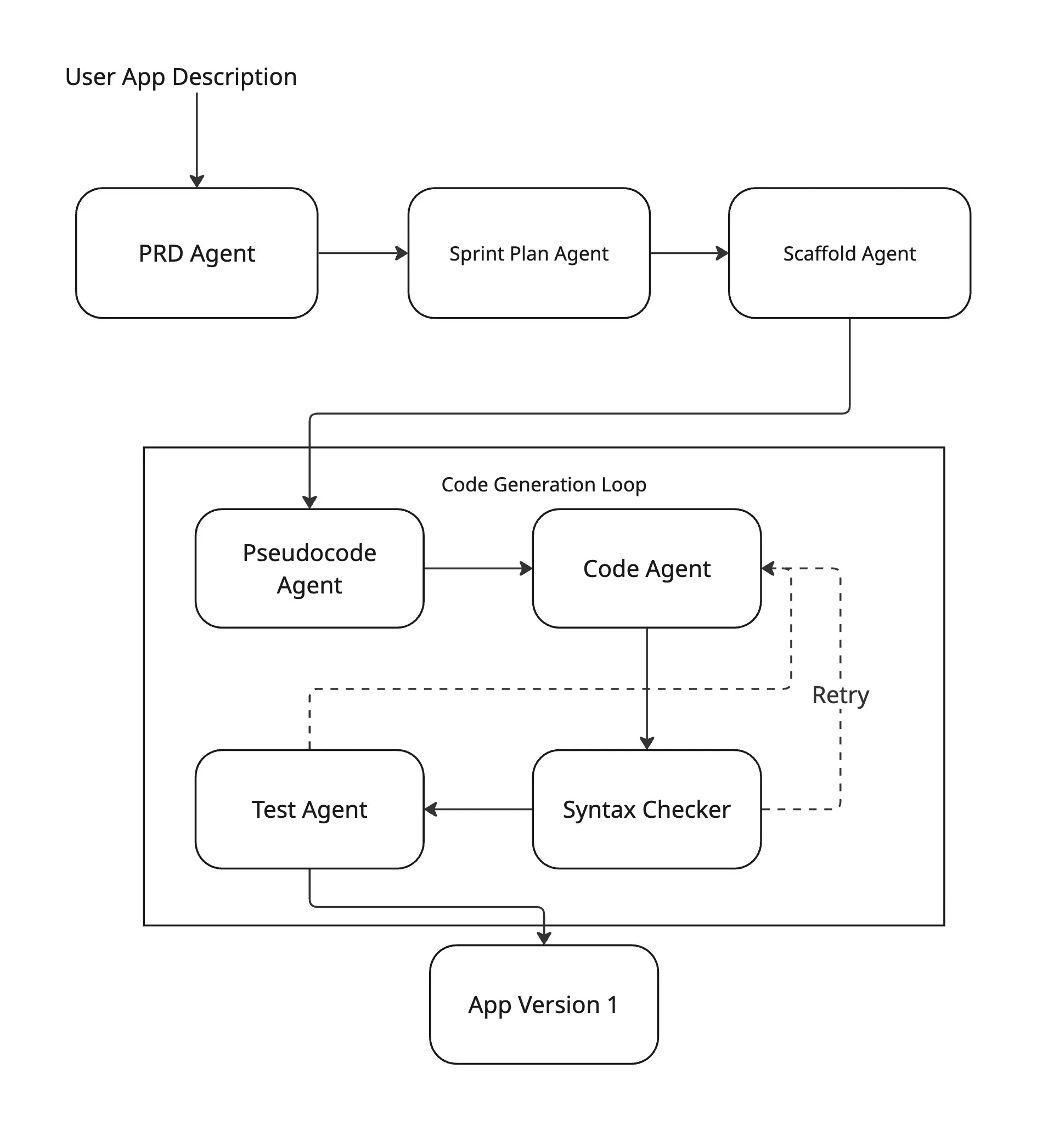
Six agents, six roles:
- PRD Agent — takes a raw feature description and produces a structured Product Requirements Document
- Sprint Planner — decomposes the PRD into development tasks with explicit dependencies
- Scaffolding Agent — generates the Flutter project structure from the sprint plan
- Pseudocode Agent — writes implementation pseudocode for each component
- Code Agent — converts pseudocode to production Flutter/Dart code, with an automated syntax-check retry loop
- Test Agent — generates unit and widget tests per component
The long middle: tinkering, breaking, rebuilding
I want to be honest about this part, because I think it's the part most "here's my AI pipeline" posts skip over.
Building the first version was relatively fast. Getting it to work reliably took months.
My first prototype was a simple LangChain chain, one big sequential pipe. It broke on the second real app. The problem wasn't the LLMs; it was that mobile app generation is not a linear process, and that context for each agent need to be carefully selected. The code agent fails a syntax check? You need to retry just that node, not restart everything. Requirements are vague? You need to branch and gather more context before scaffolding. Generated code compiles but doesn't match the PRD? You need to loop back with context from the mismatch.
I then moved to LangGraph, which models all of this as a state machine. You define nodes, edges, and conditional edges. The graph state carries everything: PRD, current code, error logs, retry count, and each node gets exactly the slice it needs.
class AppState(TypedDict):
feature_brief: str
prd: Optional[PRDDocument]
sprint_plan: Optional[SprintPlan]
app_code: Optional[str]
syntax_errors: list[str]
retry_count: int
tests: Optional[str]
def should_retry_code(state: AppState) -> str:
if state["syntax_errors"] and state["retry_count"] < 3:
return "code_agent" # loop back
return "test_agent" # move forward
graph = StateGraph(AppState)
graph.add_node("prd_agent", run_prd_agent)
graph.add_node("code_agent", run_code_agent)
graph.add_node("syntax_checker", run_syntax_checker)
graph.add_node("test_agent", run_test_agent)
graph.add_edge("prd_agent", "sprint_planner")
graph.add_edge("sprint_planner", "scaffold_agent")
graph.add_edge("scaffold_agent", "pseudocode_agent")
graph.add_edge("pseudocode_agent", "code_agent")
graph.add_edge("code_agent", "syntax_checker")
graph.add_conditional_edges("syntax_checker", should_retry_code)
But even with the right architecture, the agents themselves needed endless refinement. I spent more time on prompt engineering than on any other single thing. Getting agents to stay consistent across a six-node pipeline, to not hallucinate APIs, to respect the constraints set by upstream agents, to produce structured output consistently, etc. That was a big part of work.
Every agent produces a Pydantic model, not raw text. The PRD agent returns a PRDDocument. The sprint planner returns a SprintPlan. The code agent returns a GeneratedComponent with code, filename, and dependencies. This sounds like a small detail, but it is mandatory in complex multiagents flows.
class PRDDocument(BaseModel):
app_name: str
features: list[Feature]
tech_stack: TechStack
constraints: list[str]
class Feature(BaseModel):
id: str
title: str
description: str
acceptance_criteria: list[str]
dependencies: list[str]
I tinkered with prompts. I restructured handoffs. I added guardrails, removed guardrails, added different guardrails. I tried different models and different flows. Some weeks felt like I was going backwards. But the metrics kept improving, slowly, then noticeably.
The template breakthrough
One decision changed the economics of the whole system.
The first version built every app from scratch. It worked, but it was slow and expensive, introduced a lot of unreliability, compatibility problems and every feature meant regenerating common patterns like authentication, navigation, and data fetching from zero.
I restructured the approach around modular templates: a catalogue of pre-built, hand made feature modules (marketplace, user profiles, payments, feeds). Instead of generating everything, the scaffold agent now selects and configures modules, and the code agent only writes the parts that are actually unique to this app.
This halved API costs. More importantly, it slashed hallucination errors. When the code agent is extending real, working Dart code instead of inventing it from nothing, it stays grounded. Fewer phantom APIs. Fewer impossible function signatures. Fewer things that look right but aren't. It also allowed to share interdependant context, as the schemas were already defined for the most part.
It felt like an optimization at first. It turned out to be architectural. I wish I'd done it from day one.
The result: a functioning app from a description
After months of iteration, we had something that genuinely worked. A user would describe the app they wanted. Their requirements, their features, their constraints. The pipeline would take that description and produce a functioning Flutter application. Not a prototype. Not a skeleton. A working app with real business logic, navigation, state management, and tests.
Was it perfect? No. That was never the goal. The goal was to get 90% of the way there automatically, so that human engineers could spend their time on the last 10%.
And that's exactly what happened. An engineer would pick up the generated app, run through it, test everything, fix the edge cases the model missed, add the product-specific polish. Six hours of focused human work instead of forty hours of mostly mechanical translation.
By the numbers
Over six months in production:
- Development time: 40 hours → 6 hours per application (85% reduction)
- Code quality: 90%+ of generated code passes review with minor edits
- Cost per app: roughly $4–10 in LLM API costs
The remaining six hours is the work that actually matters: review, edge cases, and the kind of product-specific customization that no model can anticipate.
What I learned
The weeks I spent just observing and timing the existing process felt slow, but they were the most important weeks of the project. Without that map, I would have optimized the wrong things. And it always turns out that we didn't spend enough time planning.
Each individual agent is relatively straightforward. Making them work together, keeping context coherent across six nodes, handling failures gracefully, ensuring structured outputs flow cleanly from one to the next is where the real complexity lives.
Building from reusable, grounded modules instead of generating from scratch should have been the default from the beginning.
Allow for gradual improvement. Low coupling and high cohesion. Without that, finding where the improvements shoudl come from and how to tackle them becomes impossible. It was the local improvments that allowed such results. The pipeline didn't go from 40 hours to 6 overnight. Each version was a little better, a little more reliable. That compounding is what made the final result possible.